Hydra Connect 2016: Workshops
- Bill Branan
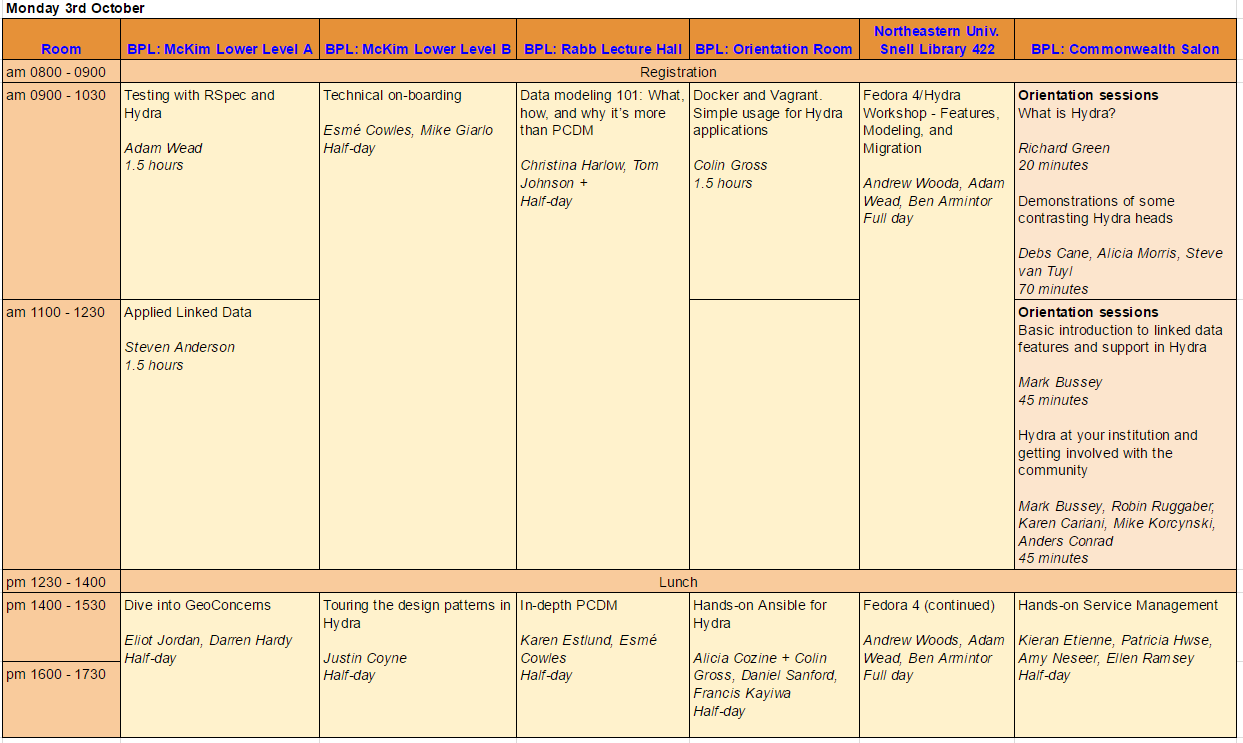
.
See Hydra Connect 2016: Orientation sessions for details of the Orientation Sessions shown in the last column.
Workshop session details (alphabetical order)
All the workshops will be held at the Boston Public Library with the exception of the Fedora workshop which will take place in Room 422 of the Snell Library at Northeastern University.
Steven Anderson
Length 90 minutes in BPL: McKim Lower Level A, 11.00-12.30
Audience: intermediate / advanced with a solely developer focus.
This workshop is all about techniques to use linked data within your Hydra based application. For example, autocomplete fields from a controlled vocabulary are nice... but what if you wanted to give more context to what users are selecting via things like alternative labels and broader / narrower concepts? How do you cache triples locally? How do do you publish your own controlled vocabulary for others to use? And what is the best way to make your RDF data harvestable by others? This workshop is based on work done by the Applied Linked Data working group:https://wiki.duraspace.org/display/hydra/Applied+Linked+Data+Working+Group
Data Modeling 101: What, How, and Why it’s more than PCDM
Julie Hardesty, Christina Harlow, Tom Johnson and Mark Matienzo
Length: Half day in BPL: Rabb Lecture Hall, 9.00-12.30
Audience: All (audience experience and expertise diversity is welcome, as modeling is at the intersection of many systems, workflows, applications, and work areas). Audience experience level aimed at beginner - intermediate.
This will be a half-day, hands-on workshop covering data modeling primarily in RDF. We hope to bring a diverse group of Hydra community members together to learn, discuss, and build out examples that will inform Hydra community best practices for data modeling. This modeling work will be taught in the context of helping Hydra and Fedora development, metadata, and interoperability efforts. We will discuss how model uses a number of standards, and demo the different ways to represent models. We will compare and contract data modeling with metadata standards/profiles. We will walk through modeling efforts around PCDM and its place in our work and community - this workshop will not focus on PCDM alone (this is not a PCDM or RDF workshop). We want this workshop to bring together, develop and engage a larger corps of data modelers in the Hydrasphere. Laptops with internet connection strongly recommended.
Dive into GeoConcerns
Eliot Jordan, Darren Hardy
Length: Half day in BPL: McKim Lower Level A, 2.00-5.30
Audience: Managers, developers
This workshop focuses on hands-on exercises with GeoConcerns, a new PCDM-based Fedora 4 reference implementation for geospatial resources in a repository (see http://geoconcerns.github.io), and we welcome developers and managers alike to participate. These exercises will include modeling content in Fedora 4 using Hydra’s PCDM data model. Furthermore, participants will install and configure the GeoConcerns software on their laptops, and learn how to structure and “wrangle” geospatial data for ingest.
We will discuss how to develop scaleable and sustainable digital repository services for geospatial resources using open, collaborative approaches. Participants will learn about data modeling and metadata requirements for curation of a wide-variety of geospatial content types, including historic scanned maps, vector data, raster data, and georectified maps. The instructors contribute to open source communities, including OpenGeoMetadata, GeoBlacklight, and Hydra, and have practical experience building production-quality geospatial repository services.. Participants will require laptops with VirtualBox and Vagrant installed to follow along with the workshop. Instructions will be provided beforehand where possible; otherwise, participants can do the installations at the workshop.
Docker and Vagrant. Simple usage for Hydra applications
Coiln Gross
Length: 1.5 hours in BPL: Orientation Room, 9.00-10.30
Audience: Intermediate Developers
A Dive-into-Hydra style walk-through of using Docker and Vagrant to develop and deploy a vanilla Curation Concerns application. Workshop will include: a simple demonstration using docker to containerize solr and fedora; a more complex demonstration using vagrant as a deployment target. For follow along, participants will require a system with Vagrant 1.8.4 or higher and Docker 1.11.2 or higher.
Vagrant: https://github.com/grosscol/present-vagrant-docker
Docker: https://github.com/mlibrary/sufia-compose
Fedora 4/Hydra Workshop - Features, Modeling, and Migration
Updated info 2016-09-27
NB: This workshop will be held in Snell 422 (the library classroom) at Northeastern University
Andrew Woods, Adam Wead & Ben Armintor
Length: Full day in Snell Library Room 422 at Northeastern University, 9.00-5.30
Audience: Developers
Fedora is the flexible, extensible, open source repository platform that stores and preserves linked data resources, and is used as the underlying platform by Hydra for managing content. Fedora is used in a wide variety of institutions including libraries, museums, archives, and government organizations. Fedora 4 introduces native linked data capabilities and a modular architecture based on well-documented APIs and ease of integration with existing applications.
Both new and existing Hydra/Fedora users will be interested in learning about and experiencing Fedora 4 features and functionality first-hand. In addition to working directly with the core Fedora RESTful services, this workshop will include focus on using a Portland Common Data Model approach to modeling Hydra/Fedora resources. The hands-on modeling exercises will be performed in the context of migrating provided resources into a new Hydra/Fedora repository.
Attendees will be given pre-configured virtual machines that include a Fedora 4 Hydra stack bundled with the Solr search application and a triplestore that they can install on their laptops and continue using after the workshop.
Part 1 - Core Fedora features
** Hydra expectations on Fedora
** CRUD
** Versioning
** Fixity
Part 2 - Hydra/PCDM modeling
** ActiveFedora modeling basics
** PCDM and Hydra
Part 3 - Migration
** Migration in action
Part 4 - Migration
** Migration in action
Hands-on Ansible for Hydra
Alicia Cozine + Colin Gross, Daniel Sanford, Francis Kayiwa
Length: Half-day in BPL: Orientation Room, 2.00-5.30
Audience: This workshop is aimed at developers and sysadmins at any experience level. Systems-curious managers/others are welcome too as long as they are prepared to participate in the hands-on exercises.
Learn to use Ansible (an automation and configuration management tool) in the context of building and maintaining Hydra servers. No prior Ansible experience necessary, but attendees should be comfortable working at the command line and bring a laptop with Ansible, Vagrant, and VirtualBox pre-installed (we’ll provide instructions when you register - Windows users, please identify yourselves ahead of time). Topics include Ansible terminology (playbooks, roles, tasks, handlers, vars, defaults, etc.), how Ansible works, Ansible gotchas, using the Ansible documentation, and a guided tour of the ansible-hydra repo. We will use Ansible to build a production-like Hydra vagrant box and answer questions about Ansible usage, tools, limitations, and more. If there’s both time and interest, we may work on tickets from the ansible-hydra repo. Attendees should come with laptops pre-loaded with Ansible, Vagrant, and VirtualBox.
Hands-on Service Management
Kieran Etienne, Patricia Hswe, Amy Neeser, Ellen Ramsey
Length: Half day in BPL: Commonwealth Salon, 2.00-5.30
Audience: managers, product owners (all levels)
This workshop will provide an overview of service management best practices, with a focus on roles and responsibilities, communication strategies, and assessment. Participants will hear from service managers in the Hydra community, engage in discussion and hands-on activities, and come away with tips, tricks, and tools for service management planning and execution.
In-depth PCDM - what it is? what it does? how it works? how to implement? new developments?
Esmé Cowles, Karen Estlund
Length: Half day in BPL: Rabb Lecture Hall, 2.00-5.30
Audience: all, but prior experience with data modeling (such as the "Basic introduction to linked data and related concepts in Hydra" session) will help greatly.
The Portland Common Data Model (PCDM) is a flexible shared, linked data-based domain model for representing complex digital objects. This workshop will review PCDM, its history, technical overview, recent developments, and Hydra-specific implementation considerations. The workshop will also include an interactive modeling session where users will employ use cases from their repositories (or provided samples) to model in PCDM. The goals of the workshop include: increasing familiarity with PCDM, contributing back to PCDM from the activities of the participants, and increasing participants’ familiarly and comfort with data models more broadly. Attendees who want to walk through CurationConcerns to see how the data is modeled in Hydra and stored in Fedora and Solr should setup a Vagrant virtual environment following the instructions at https://github.com/projecthydra-labs/hydra-vagrant.
Technical On-Boarding - discussion of how to contribute code at the community level
Esmé Cowles, Mike Giarlo
Length: Half day in BPL: McKim Lower Level B, 9.00-12.30
Audience: new developers, or developers or managers who will be on-boarding new developers
This workshop will walk you through the nuts and bolts of participating in Hydra development, including:
• What's a CLA and why do I need one?
• Why does my code need tests (aka, why did my Pull Request get rejected)?
• What does squashing commits mean?
• How big is too big (aka, how can I make my code easier to review)?
• Where do I get help (how do all the different communication channels work — where should I try first)?
• How do I bring new developers at my institution into the Hydra community?
Attendees should have a laptop with a Git client for hands-on Git demonstrations.
Testing with Rspec and Hydra
Adam Wead
Length: 90 minutes in BPL: McKim Lower Level A, 9.00-10.30
Audience: Developers, new and old - geared towards current Hydra adopters or people who have just started working on application
This will be a reprise of a workshop given at Hydra Connect 2014, but improved and updated to cover new issues with the PCDM stack of gems, as well as strategies for test refactoring and speed improvement. The workshop will go over testing practices for each of the principle unit components of an application (models, controllers, views, jobs, services, etc.) and also contrast that with how feature tests and written. Takeaways will include some "boilerplate" examples for each kinds of test, test suite configuration, continuous integration, and if time permits, one-on-one help with individual questions or blockers that anyone might be currently having. Having a laptop and working Hydra application is a must, even if it's just the barebones. Ideally, this workshop is geared towards current Hydra adopters or people who have just started working on applications. Someone who has never used Hydra or Rspec would probably struggle with it.
Touring the design patterns in Hydra
Justin Coyne
Length: Half-day in BPL: McKim Lower Level B, 2.00-5.30
Audience: Developers
Forms, Presenters, Actors, Indexers, Renders, and Services are all patterns used in the latest versions of CurationConcerns and Sufia. Join us for an exploration of what these patterns look like. We will reveal where they appear in the code and how you can best add customization to make Hydra work for you. Participants will need a laptop with a copy of VirtualBox, and Vagrant 1.8.5+ loaded. Before arriving please create a new directory, and copy this file into the new blank directory: http://camp.curationexperts.com/Vagrantfile
mkdir tutorial
cd tutorial
curl http://camp.curationexperts.com/Vagrantfile -o Vagrantfile
vagrant up